Oracle11g迁移数据到Oracle19c
1.准备工作
1.1 确定迁移用户
确定迁移用户的默认表空间和临时表空间。
col username for a10;
col default_tablespace a20;
col temporary_tablespace a20;
select username,default_tablespace,temporary_tablespace,account_status from dba_users where account_status='OPEN';

1.2 确认数据库实例使用字符集
需确保两个数据库实例字符集一致。
select userenv('language') from dual;
1.3 查看表空间信息
col tablespace_name for a20;
col file_name for a50;
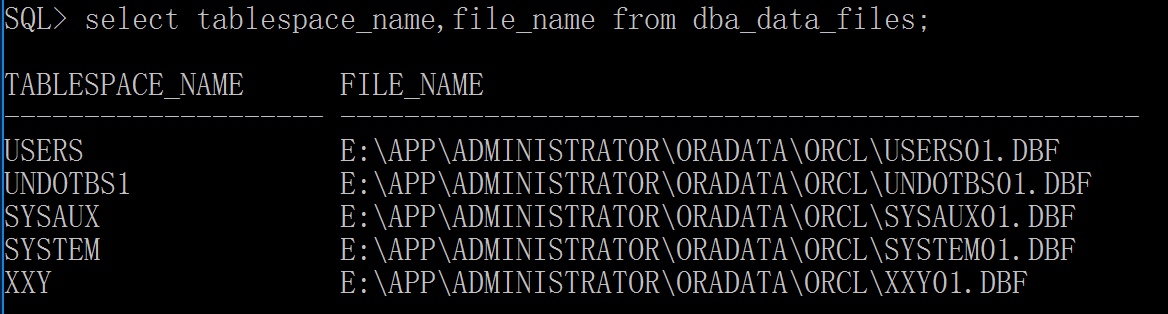
select tablespace_name,file_name from dba_data_files;
--查看指定用户都用了哪些表空间
select distinct tablespace_name from dba_segments where owner = 'XXX';
1.4 查看迁移用户下对象数量
select object_type, count(*) from dba_objects where owner = 'XXY' group by object_type order by 1;

--job数量
--DBMS_SCHEDULER 创建的作业和 DBMS_JOB 创建的作业是通过两个不同的机制管理的,它们的信息存储在不同的数据字典视图中。
select schema_user,count(job) from dba_jobs group by SCHEMA_USER;
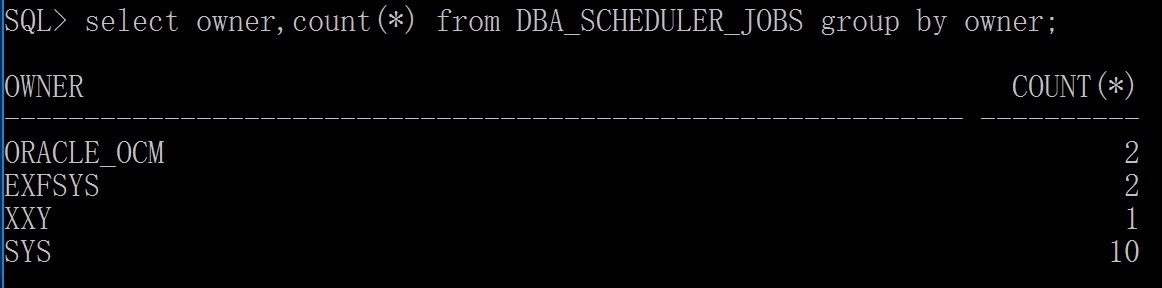
select owner,count(*) from DBA_SCHEDULER_JOBS group by owner;

1.5 查询迁移用户拥有角色权限
select grantee,granted_role,admin_option,default_role from dba_role_privs where grantee='XXY';

1.6 记录 public 对象
select owner,synonym_name from dba_synonyms where owner='XXY';
1.7 锁定用户,KILL 会话
防止备份过程中数据发生变化,若服务均已停止可跳过。
alter user xxy account lock;
--查看 XXY 用户当前会话
select SID,SERIAL#,USERNAME,MACHINE,PROGRAM from gv$session where username='XXY';
--拼接 KILL 会话语句
select 'alter system kill session '''|| SID ||',' ||SERIAL# ||''''||'immediate;' as KILL from gv$session where username='XXY';
--执行KILL语句
--停止作业调度
alter system set job_queue_processes=0;
2.数据迁移
2.1 使用数据泵导入导出
无需在新库创建旧库用户信息,导入后会自动创建和旧库一样状态的用户,但需要提前准备好和旧库名称一样的表空间文件。
2.1.1导出数据
2.1.1.1 创建备份逻辑目录
创建目录需要 create directory权限。
create or replace directory backup as 'E:\backup';
grant read,write on directory backup to xxy;
E盘下新建backup文件夹。

2.1.1.2 导出数据
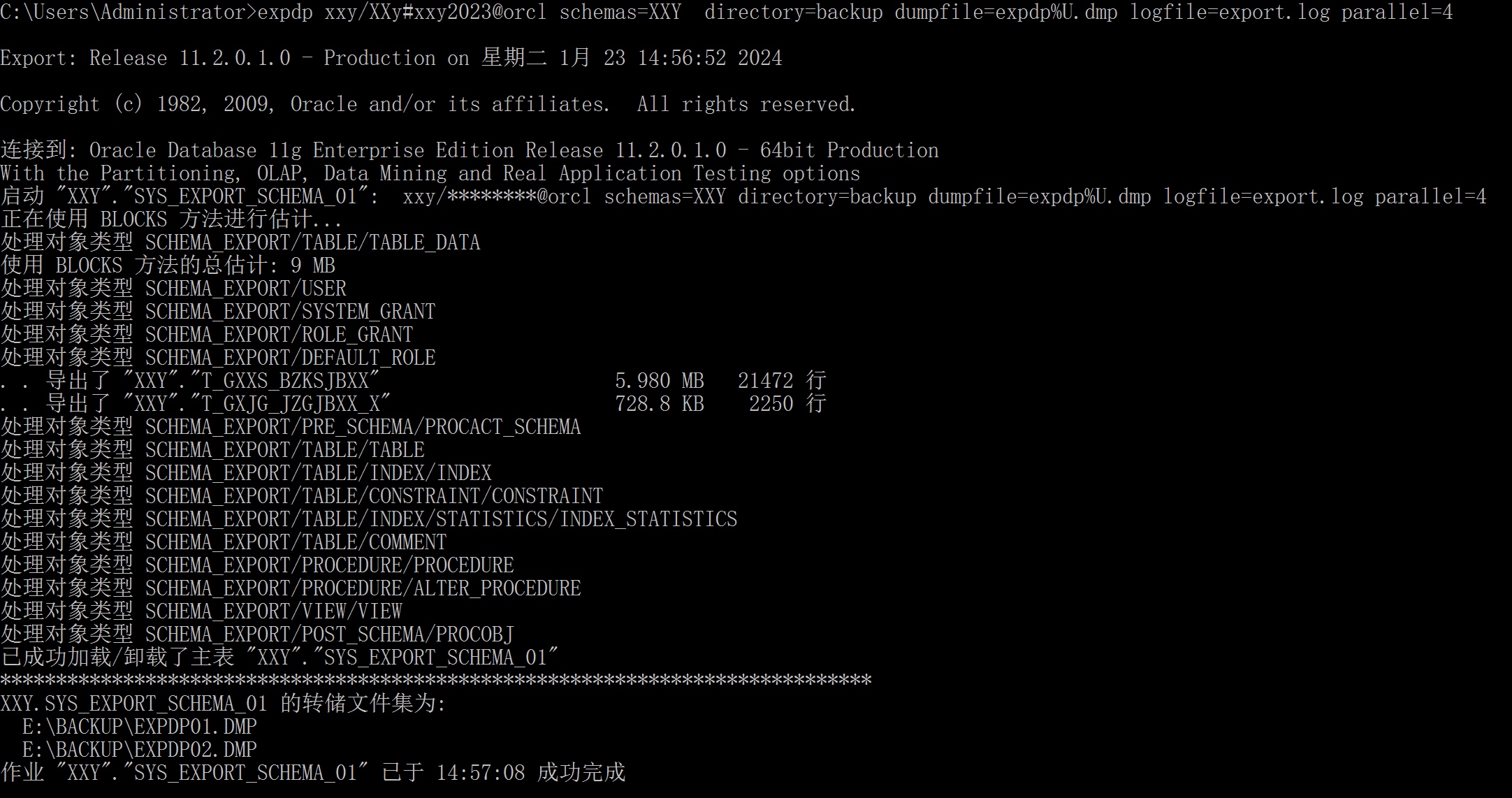
expdp xxy/XXy#xxy2023@orcl schemas=XXY directory=backup dumpfile=expdp%U.dmp logfile=export.log parallel=4
这是我设置的并行通道为4但是只导出了两个DMP文件,因为数据量比较少。

2.1.2 导入数据
2.1.2.1 创建导入逻辑文件夹
create or replace directory IMPDP_DIR as '/opt/impdir';
grant read,write on directory IMPDP_DIR to system;
2.1.2.2 创建表空间
根据 1.1 查询到的用户默认表空间和临时表空间,在新数据库建名称一样的表空间。
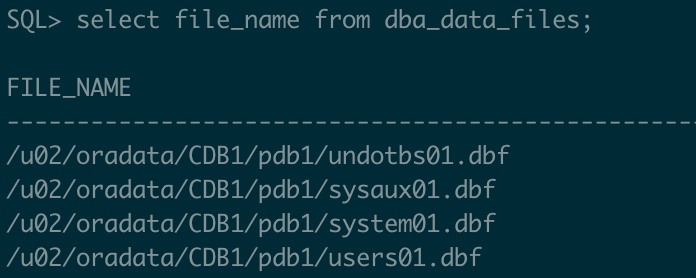
--查看当前表空间存放位置
select file_name from dba_data_files;
--创建表空间
create tablespace XXY logging datafile '/u02/oradata/CDB1/pdb1/xxy01.dbf' size 1000m autoextend on next 100m maxsize unlimited;

2.1.2.3 导入数据
将导出的数据文件放到上一步创建的导入逻辑文件,若要修改SCHEMA添加remap_schema=SCOTT:NEW_SCOTT参数。
impdp system/XXy#system2023@pdb1 directory=IMPDP_DIR dumpfile=EXPDP%U.DMP logfile=importDB19c.log parallel=4
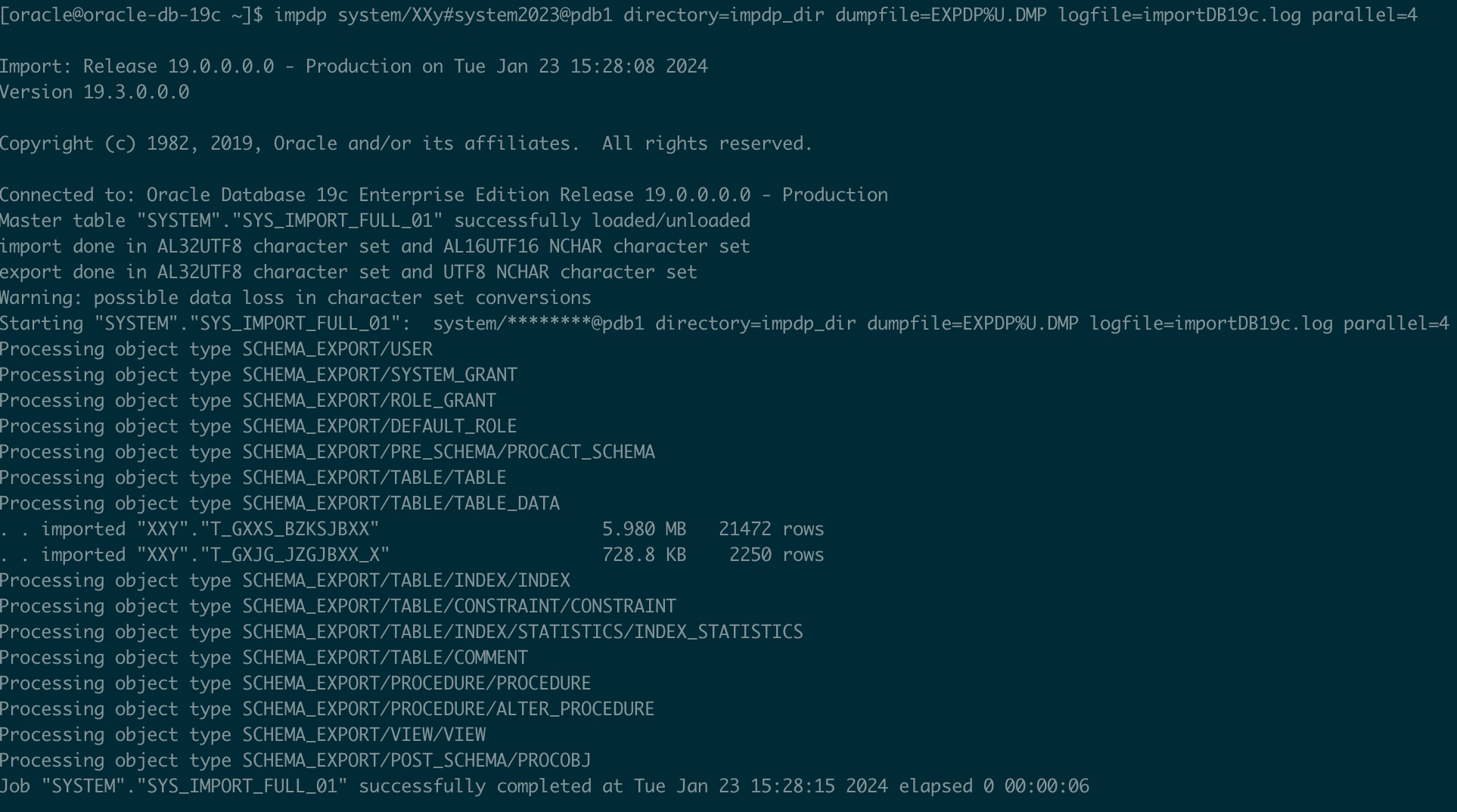
注意:如果oracle用户没有导入文件夹的权限会报错 chown -R oracle:oinstall impdir/ 若两个实例字符集不一样,则使用 CHARACTERSET=XXX 参数,通常不建议这么做,因为错误地使用这个参数可能会导致数据损坏。
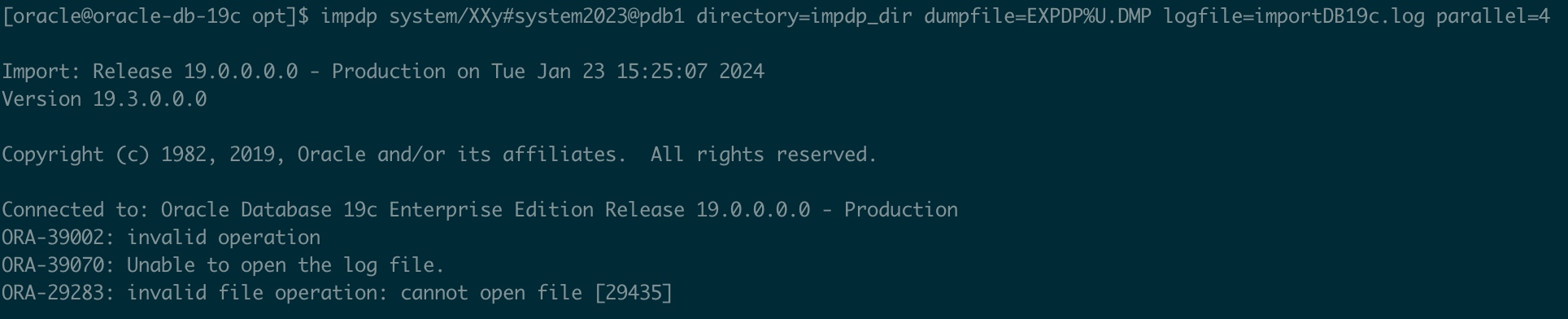
2.2 使用传输表空间
只传输数据文件和元数据,不涉及数据的实际导入导出,适合大型数据库。仅传输表空间内的数据,不包括其他数据库对象或结构。因此,视图、存储过程、函数、序列等对象不会随表空间一起传输。
2.2.1 数据导出
2.2.1.1 执行检查
执行DBMS_TTS.TRANSPORT_SET_CHECK过程来对要传输的表空间进行检查,需要EXECUTE ON DBMS_TTS权限,可使用SYS用户执行。你需要提供你想检查的表空间名称的列表,并指定是否要包括依赖性检查。
- ts_list 参数是你想要检查的表空间名称,用逗号分隔。
- incl_constraints 参数指定是否检查引用约束。如果设置为 TRUE,则检查会包括对表空间中的所有引用约束的检查。
BEGIN
DBMS_TTS.TRANSPORT_SET_CHECK(ts_list => 'XXY', incl_constraints => TRUE);
END;
/
查看TRANSPORT_SET_VIOLATIONS视图是否有违规项。如果表空间是自包含的,这个视图应该是空的。
SELECT * FROM TRANSPORT_SET_VIOLATIONS;
2.2.1.2 使表空间只读
ALTER TABLESPACE XXY READ ONLY;
2.2.1.3 导出数据
需要先创建导出逻辑文件夹,参考 2.1.1.1。
--导出元数据
expdp system/XXy#system2023@orcl DIRECTORY=backup DUMPFILE=EXPDP.DMP TRANSPORT_TABLESPACES=XXY logfile=export.log
--导出其他对象,确保INCLUDE里包含了所有对象,DBMS_JOB 创建的作业需要先迁移到 DBMS_SCHEDULER
expdp system/XXy#system2023@orcl DIRECTORY=backup DUMPFILE=XXY_EXPDP.DMP LOGFILE=export_xxy.log SCHEMAS=XXY INCLUDE=VIEW, PROCEDURE, FUNCTION, SEQUENCE, PACKAGE, TRIGGER, PROCOBJ, TYPE, DB_LINK, MATERIALIZED_VIEW, SYNONYMS
--迁移 DBMS_JOB
BEGIN
DBMS_SCHEDULER.CREATE_JOB (
job_name => 'new_scheduler_job_name',
job_type => 'PLSQL_BLOCK',
job_action => 'BEGIN ... END;', -- 替换为实际的 PL/SQL 代码块
start_date => SYSTIMESTAMP,
repeat_interval => 'freq=daily; byhour=0; byminute=0; bysecond=0', -- 每天午夜执行
enabled => TRUE
);
END;
/
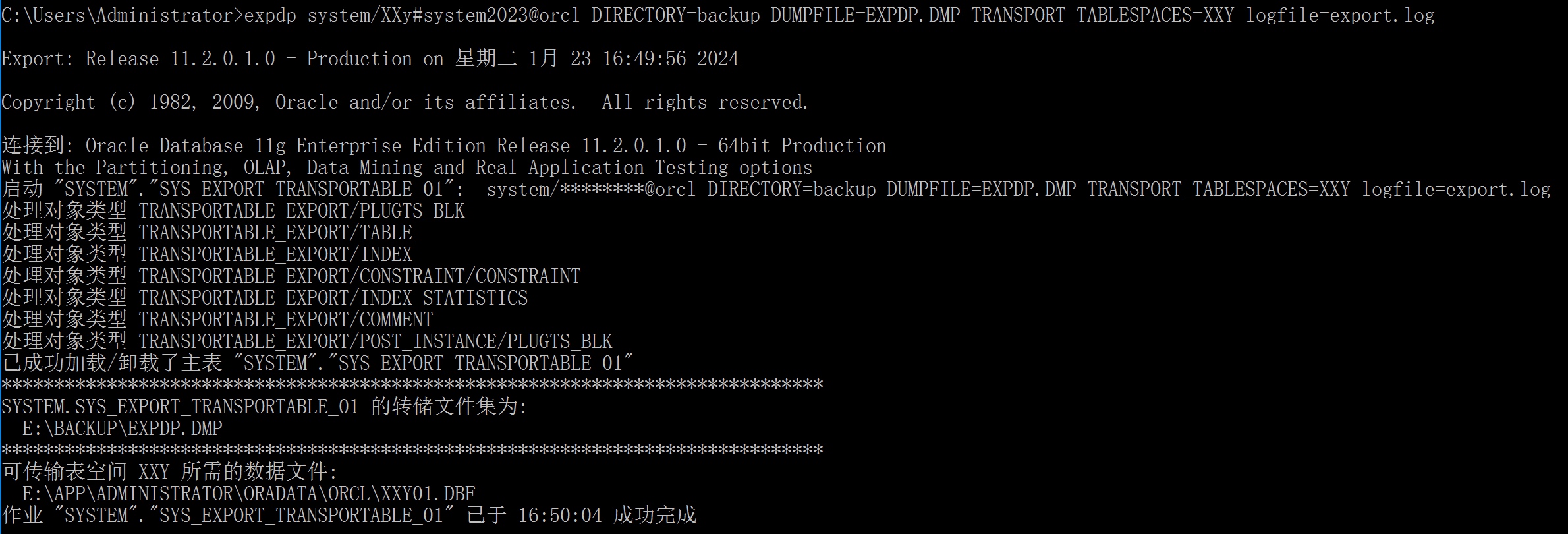
2.2.2 数据导入
2.2.2.1 创建用户
create user xxy identified by Xxy#xxy2023;
grant CONNECT,RESOURCE,DBA to XXY;
2.2.2.2 数据导入
将导出的除数据文件外文件放到IMPDP_DIR路径下,数据文件放到数据库数据目录下,确保oracle用户有/opt/impdir/和数据文件的权限。
--导入元数据
impdp system/XXy#system2023@pdb1 DIRECTORY=IMPDP_DIR DUMPFILE=EXPDP.DMP TRANSPORT_DATAFILES=/u02/oradata/CDB1/pdb1/XXY01.DBF logfile=importDB19c.log
--导入其他对象
impdp system/XXy#system2023@pdb1 directory=IMPDP_DIR dumpfile=XXY_EXPDP.DMP schemas=XXY logfile=importDB19c_XXY.log
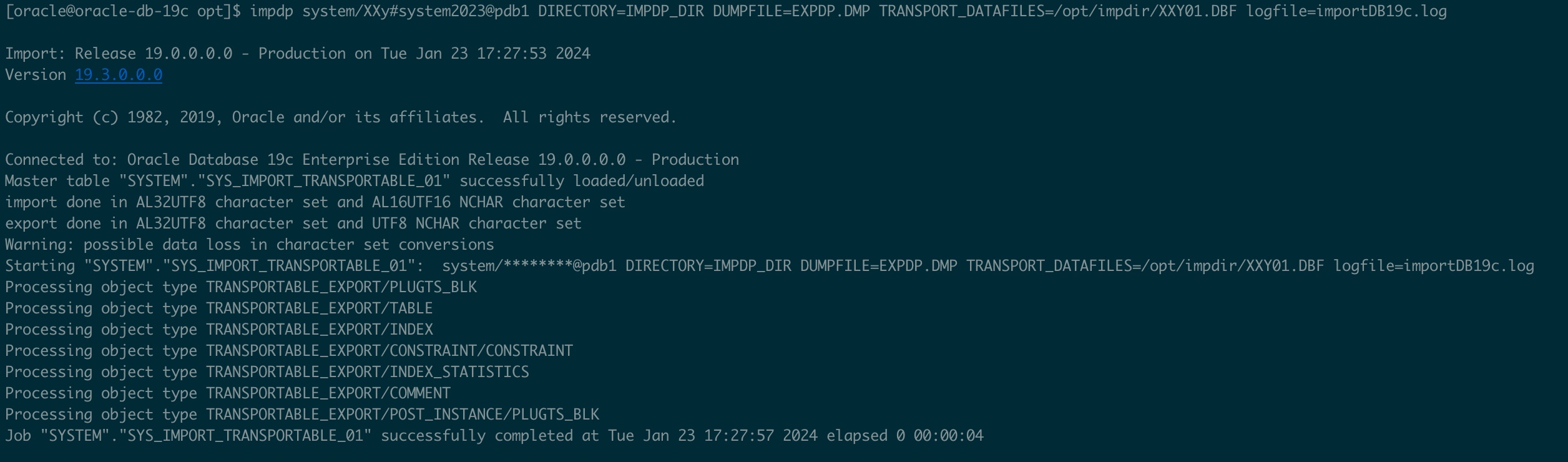
2.2.2.3 将表空间置为读写模式
ALTER TABLESPACE XXY READ WRITE;
2.2.2.4 修改用户默认表空间
ALTER USER XXY DEFAULT TABLESPACE XXY;
2.3 IMPDP 网络导入
网络导入(Network Import)功能可以直接从一个数据库向另一个数据库导入数据,无需事先导出到磁盘文件。这种方式允许数据在两个数据库之间直接传输,节省了磁盘空间并可能加快导入过程。网络导入特别适用于数据库迁移和大量数据的快速传输。
2.3.1 导入准备
2.3.1.1 创建DBLINK
在新库中创建指向旧库的 DBLINK。
CREATE DATABASE LINK orcl11g
CONNECT TO XXY IDENTIFIED BY XXy#xxy2023
USING '(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=172.16.22.142)(PORT=1521))(CONNECT_DATA=(SERVICE_NAME=orcl)))';
--查看
SELECT * FROM DBA_DB_LINKS;
--测试连接
SELECT 1 FROM dual@orcl11g;
2.3.1.2 创建用户和表空间
可以只创建表空间。
create tablespace XXY logging datafile '/u02/oradata/CDB1/pdb1/xxy01.dbf' size 1000m autoextend on next 100m maxsize unlimited;
create user xxy identified by Xxy#sys2023 default tablespace XXY;
grant DBA,RESOURCE,CONNECT to xxy;
2.3.2 数据导入
2.3.2.1 通过网络导入
impdp system/XXy#system2023@pdb1 network_link=orcl11g directory=IMPDP_DIR logfile=network_import.log
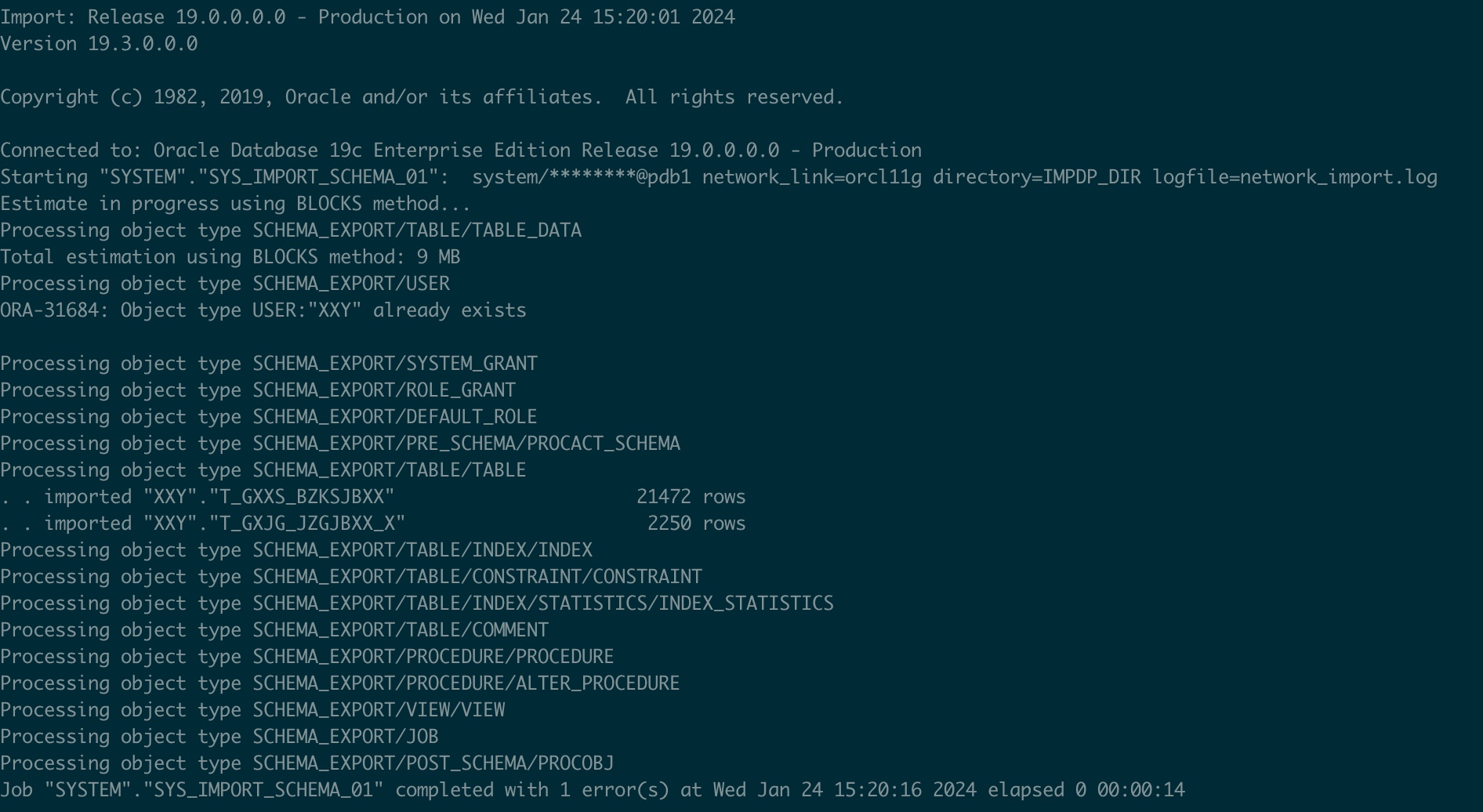
3.检查
3.1 检查对象数量
参考 1.4,不同版本数量可能不一样,确定包含低版本的内容。
3.2 检查是否存在失效对象
使用数据库连接工具或者命令行检查,连接工具更好操作。
select owner, object_type, status, count(*) from dba_objects where status='INVALID' group by owner, object_type, status order by owner, object_type;
--生成编译对象SQL
SELECT
CASE
WHEN OBJECT_TYPE = 'PACKAGE' THEN
'ALTER PACKAGE ' || OWNER || '.' || OBJECT_NAME || ' COMPILE;'
WHEN OBJECT_TYPE = 'PACKAGE BODY' THEN
'ALTER PACKAGE ' || OWNER || '.' || OBJECT_NAME || ' COMPILE BODY;'
WHEN OBJECT_TYPE = 'FUNCTION' THEN
'ALTER FUNCTION ' || OWNER || '.' || OBJECT_NAME || ' COMPILE;'
WHEN OBJECT_TYPE = 'PROCEDURE' THEN
'ALTER PROCEDURE ' || OWNER || '.' || OBJECT_NAME || ' COMPILE;'
WHEN OBJECT_TYPE = 'TRIGGER' THEN
'ALTER TRIGGER ' || OWNER || '.' || OBJECT_NAME || ' COMPILE;'
ELSE
'ALTER ' || OBJECT_TYPE || ' ' || OWNER || '.' || OBJECT_NAME || ' COMPILE;'
END AS COMPILE_STATEMENT
FROM
DBA_OBJECTS
WHERE
STATUS = 'INVALID'
ORDER BY
OBJECT_TYPE, OWNER, OBJECT_NAME;
--编译失效对象
alter package <schema_name>.<package_name> compile;
alter package <schema_name>.<package_name> compile body;
alter view <schema_name>.<view_name> compile;
alter trigger <schema_name>.<trigger_name> compile;
3.3 检查用户定义
select owner,type_name,typecode from dba_types where owner='XXY';